前端工作中,经常会遇到将 Word 文档转换为 HTML 页面的需求,大多数是一些协议、规则,内容为纯文本;
实际操作的时候,需要把 word 文档中的内容复制出来,放到 html 标签中,并添加 css 进行格式化,因为涉及到分段、正文、子标题等,往往没法整体复制,整个过程费时费力;
更新时,也需要在一大段文案中做修改,容易出错;
概述
word 文档可以另存/导出为 html,如果对导出的 html 进行格式化,就可以极大的减少工作量,基于此,完全可以建立一个自动导出文档并格式化的流程;
基本思路:使用 python,调用 Office 底层 API 将 word 文档导出为单页 html,之后对此 html 进行格式化(正则替换处理);
- python 版本:python2.7.x
- office 版本: 2010
- 系统环境:windows 7 / windows 2008 r2
需要安装的 python 包:
- pywin32:使 python 可以调用 windows API,可操作 word 转为 html;Github地址:http://github.com/mhammond/pywin32;
- chardet:检测字符编码,读取一个文件后,如果进行转码,需要知道当前的编码才能进行转换;资源地址:http://pypi.org/project/chardet/;
Word 导出类型
实际操作之前,先看一下 word 可以导出的类型,随便打开一个 word 文档,点击左上角“文档” – “另存为”,支持导出的类型如下图:
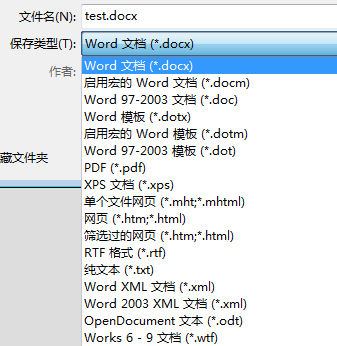
既然支持网页,那就省了好多事情,格式化一下就能用了,相关类型:
- 单个文件网页:格式为 MHTML,文档的所有内容都存到了这一个文件中,格式和内容太过复杂,不好处理;
- 网页:格式为 HTML,这种类型有两个问题,一是会生成“文件名.files”的资源文件夹;二是生成的 html 中,也包含了大量描述 word 信息的 xml 片段;
- 筛选过的网页:格式为 HTML,内容为常规HTML,基本没有多余的无用信息,完全符合要求;需要注意一点,保存的时候,会有一个提示,直接确定就好了,因为是纯文本的,不会存在什么特定功能;

所以,我们需要另存的类型为”筛选过的网页”。
具体的相关操作函数如下,传入 word 文档地址和最终要导出的 html 地址,返回导出 html 的字符串,基本逻辑是打开文档 – 另存为 HTML – 读取 HTML 内容
# docPath - word 文档地址 exportPath - 导出的 html 地址
def wordToHtml(docPath, exportPath):
try:
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(docPath)
doc.SaveAs(exportPath, 10)
finally:
if ('doc' in dir()) and doc.Close:
doc.Close()
if ('word' in dir()) and word.Quit:
word.Quit()
f = open(exportPath, 'r')
str = f.read()
f.close()
return str代码中有几个地方需要注意:
- 判断一个变量是否存在,用 ‘变量名’ in dir();
- Python 中读取文件也非常简单,open() – read() – close()
- SaveAs 第二个参数,表示另存的类型;10 – “筛选过的网页”,0 – “Word 97-2003 文档”,其他的类型对照表如下:
名称 值
wdFormatDocument = 0
wdFormatDocument97 = 0
wdFormatDocumentDefault = 16
wdFormatDOSText = 4
wdFormatDOSTextLineBreaks = 5
wdFormatEncodedText = 7
wdFormatFilteredHTML = 10
wdFormatFlatXML = 19
wdFormatFlatXMLMacroEnabled = 20
wdFormatFlatXMLTemplate = 21
wdFormatFlatXMLTemplateMacroEnabled = 22
wdFormatHTML = 8
wdFormatPDF = 17
wdFormatRTF = 6
wdFormatTemplate = 1
wdFormatTemplate97 = 1
wdFormatText = 2
wdFormatTextLineBreaks = 3
wdFormatUnicodeText = 7
wdFormatWebArchive = 9
wdFormatXML = 11
wdFormatXMLDocument = 12
wdFormatXMLDocumentMacroEnabled = 13
wdFormatXMLTemplate = 14
wdFormatXMLTemplateMacroEnabled = 15
wdFormatXPS = 18格式化
已经得到了一个原始的 HTML,接下来就可以进行格式化了;格式化步骤:
- 去除自带样式,包括 style 标签和每个元素里的 style 样式;
- 去除标签上的行为、样式属性 (valign=center、lang=EN_US等);
- 替换标签的默认 class (比如 MsoTitle 为标题,替换为自定义的class title);
- 处理特殊标签,比如标签 a 需要设置 taget,table 需要设置边框之类;
- 添加自定义样式和 js 的引用;
- * 去掉批注
- 去空:去掉空标签、内容为空格的标签、内容中的空格、空行;
逻辑基本是上面这样,实际代码太多,只截取一部分:
# res - 导出的 html
def formatHtml(res):
res = re.sub(r'charset=[\w\d\-]+', 'charset=utf-8', res)
curCode = chardet.detect(res)['encoding']
try:
res = res.decode(curCode)
except UnicodeDecodeError:
res = res.decode('gbk')
# 往head标签中添加内容
head = r'''<title></title>
<meta charset="utf-8">
<link rel="stylesheet" href="https://ashita.top/custom.css">
'''
# 去除默认style标签
res = re.sub(r'<style>[\s\S]*<\/style>', head, res)
res = re.sub(curCode, r'utf-8', res) # 改编码
# 去掉行间样式 style
res = re.sub(u'style=[\w\d;\-_.\.\s;,:#\"\'%\u4e00-\u9fa5]+>', '>', res)
# 填充title内容
searchObj = re.search(u'(MsoTitle|MsoSubtitle)[\'\"<>=\s\d\w]+([\u4e00-\u9fa5\d]+)', res, re.I | re.M)
if (searchObj):
title = searchObj.group(2)
res = re.sub(r'<title></title>', '<title>{0}</title>'.format(title), res)
# 动态参数
# res = re.sub(r'\{\{([\w\d]+)\}\}', createParams, res)这一步其实只做了一件事儿:正则替换;
语法是这样的 re.sub(正则字符串,要替换成的字符串,源字符串)
其他需要注意的地方:
- 正则真是一门艺术,熟练掌握不易;所以在处理的时候,我写的表达式尽量简单、少用模式,并不要求极高的性能;
- 字符串前加 r/R 可以表示原始字符串,即内部字符不作转义;字符串前加 u 表示创建的是一个 Unicode 字符串;
源码地址:http://github.com/sun2dan/stack/tree/master/python/word2html