最近做了一个日本IT公司招聘信息的采集,想要对日本IT环境及使用技术做一个简单的分析;
项目用的是Scrapy框架,第一次用,还是遇到不少问题;对数据进行分析是第一次;
采集、处理和分析过程中也有一些不严谨的地方;
项目地址:点击查看,抓取的数据传到百度云了:点击查看 ,密码:s7b0,spiders/job.db;
数据采集
数据来源是这两个招聘网站:http://next.rikunabi.com 和 http://tenshoku.mynavi.jp;
两个网站职位大类中,分类基本一致,和IT相关的有两个,
一个是“Web・インターネット・ゲーム”,即 “web·Internet·Game”;
另一个是“ITエンジニア”,即 “IT Engineer”;
我的数据就是从这两个大类中获取的,爬取数据的时候,都遇到点问题;
rikunabi 中,列表数据包含了五种类型,详情页又分为两种类型,列表页比较好处理,只是获取一个详情页的地址;详情页的两种类型差别很大,需要分开处理;
分页和详情页都是get方式,非常容易获取;
该网站还一个问题,就是把历史数据也显示了出来,比如下面的截图,两个大类下有 4815 个招聘信息,实际上最近一段时间的数据只有七八百条;实际操作中,我把所有数据都爬了下来,爬取的时候也没有遇到什么问题,直接拿到了全部数据;

tenshoku 中,列表数据只有一种类型,详情页有两种,不过两种差别不大,可以当做一种类型来处理;
分页是form表单提交,详情页是get方式,抓取分页数据也费了一些时间;
爬取数据的时候,每次爬取完成,都会发现少爬取了几页数据,看日志发现,每个请求都发出了,但是没有响应;在每个请求前加了定时器,停个一两秒,爬下来的数据还是会有缺失,设置时间间隔大一些应该是好使的,但这样爬取速度就太慢了;最终是手工找到爬取失败的页码,写死在程序里,爬取到这几页的数据;

爬取下来的数据,都存到了 sqlite 数据库中,除了做分析用,也可以直接查看库,做一些带条件的查询;
爬取到的数据,两个网站的数据分别放到了两个表中,这是为了调试方便,如果一个网站的数据获取有问题,直接清空再次获取就好了;最终采集完成,将数据合并到一个表中;
分析
分析数据之前,可以从招聘网站上直观地看到,分类大部分是根据业务/工作内容/职务大类来的,比如: “游戏·娱乐系统”、“系统顾问(DB,中间件)”、“程序员”、“IT架构师”,并没有国内的一些具体技术岗位,比如:“Web前端工程师”、“Java开发”、“Python”;
简单查看几则招聘信息就会发现,任职要求的范围非常广,不区分前后端和语言,比如下面这个,比较有代表性:
欢迎具备以下技能的人士:
Java,C#,HTML5,JavaScript,C++,Objective-C,Ruby,PHP,Node.js
智能手机·社交应用开发,服务器·网络设计·构建,数据库设计
业务系统开发,Web服务开发,网站创建等
如果您有以上语言以外的编程语言经验,欢迎!
这是因为日本很多公司是外包,什么类型、什么语言的项目都会接到,所以会的东西越多越好,总会用到的;
下面开始数据分析,数据样本是 rikunabi 中的新数据 和 tenshoku 中的所有数据,两者重复的数据暂不考虑(因为区分不出来,通过公司名称匹配两个网站的数据,同一公司在两个网站都发布了信息,这样的信息有69条,占总记录的3.6%);
同时,我在代码中加了一个条件,可以随意切换数据样本:所有数据、rikunabi 中的新数据 + tenshoku 中的数据、rikunabi 中的新数据、rikunabi 中的所有数据、tenshoku 中的数据;
where = ' where 1=1 and during<>"" ' # 默认为rikunabi中的新数据 + tenshoku中的数据
# where 1=1 # 所有数据
# where 1=1 and during<>"" # rikunabi中的新数据 + tenshoku中的数据
# where 1=1 and during<>"" and ntype<>"ten" # rikunabi 中的新数据
# where 1=1 and ntype<>"ten" # rikunabi 中的所有数据
# where 1=1 and ntype="ten" # tenshoku 中的数据1、基本信息
1. 1459 家公司发布了 1906 条招聘信息,平均每家发布 1.31 条信息;
2. 有 1198 家公司只发布了一条信息,占总公司数的 82.11%;
3. 发布招聘信息最多的公司有 2 家,分别发布了 11 条;
4. 有 948 家公司在东京/在东京有分公司,占总公司数的 64.98%;
5. 557 个招聘明确标注了不限学历,占总数的 29.22%;
第1点中,平均每家公司发布1.31个招聘信息,应该算是比较少的吧;
第2点中,大部分公司只发一条信息,可能和之前提到的“招聘要求范围广,公司是外包”有关,因为没有专门的职位,就写一个汇总职位的招聘信息;
第4点中,大部分公司在东京/在东京有分社,也就是说,东京的机会要多一些;
第5点中,接近30%的公司明确写了不限学历,剩下的虽然没有写,但也不一定有限制;
2、技术关键字词云

技术关键词是将任职要求、工作内容和标签的文案作为原始文本生成的,文案中,技术相关的关键字基本没有用日文书写的,所以去除了日文汉字和假名,保留了英文单词、数字和符号,然后将全角字母转为半角;
从上图可以看出,Web一词出现的频率最高,去源文本中搜了一下,发现也分了好多类:Web设计、Web应用程序、Web系统、Web服务;汉字部分都是日文假名或汉字,也就不细分了;
其次,出现频率较高的词有:Java、Python、Perl、Ruby、PHP、VB、ASP、NET、Android、OpenGL、Linux、Unix、Windows、PC、PL;
基本都是常用的技术(VB、ASP、Ruby、Perl国内很少听说了啊);
NET 指的是 .NET,
ASP 包含了 ASP 和 ASP.NET;
PL,对照源文本,这个应该是 PL/SQL;
个人对 OpenGL 的出现有些意外,可能是因为游戏吧;
下一阶梯是:VBA、COBOL、DB、Objective-C、CSS(3)、JavaScript、HTML(5)、Photoshop、ERP、CRM、SCM
COBOL 竟然还这么靠前,cobol 诞生比较早,日本用的比国内多,应该是日本电脑普及比中国早一些,那时候 cobol 比较流行吧,所以当时的大部分系统都用这个来写,后来迭代、维护中,还是有一部分系统沿用了 cobol;中国的情况可能是电脑普及过来的时候,已经有更好的编程语言可以选择了,所以国内基本没有cobol开发,这些都是我猜的,没有去查相关资料;在智联上搜cobol,公司绝大部分都是大连的对日外包…
剩下的关键词里,
kotlin、React、VR 和 AI 也比较明显,说明日本IT也没有太守旧,还是有一些新东西的;
Dreamweaver 一下回到解放前;
jQuery 出现频率也比较高,真去工作的话,这个不成问题;
右侧中间还有一个 20h,对照源文本,发现这个指的是加班时间,很多公司都写了月加班时间少于/平均 20h,呵呵,996 的话,一周就能达到20h;
RPG、2D、3D、Unity 说明日本的游戏开发机会也比较多,可惜没有做过游戏;
3、工作地点词云

原始文本取的是表中的 addr 字段,处理的时候,采用的是反向处理法,一开始,只去掉其中的html标签,然后生成词云,看是否有出现比较多的与地点无关的文字,如果有,用正则删掉,然后重新生成,重复多次后,就把地点无关出现频率高的词都删掉了,得出了上面这个结果;这样虽然会有误差,但要比我把所有地区按照名称挨个匹配出来要简单好多;
# 格式化地址内容字符串
def format_addr(str):
s1 = strQ2B(str)
s1 = re.sub(r'<[\w\d_\-!.\'\"\/\s=]+>', ',', s1)
s1 = re.sub(
r'(本社)|(リクナビNEXT上の地域分類では……)|(UIターン大歓迎です)|(Iターン歓迎)|(交通手段)|(交通)|(アクセス)|(転勤なし)|(各線)|(JR)|(市)|(府)|(県)|(その他)|(より)|(徒歩\d+分)|(東京メトロ)|(または)|(<)',
',', s1) # 東京メトロ是"Tokyo Metro",一种交通营运方式的名称,直接去掉
s1 = re.sub(r'(東京23区)|(東京都)|(東京内)', '東京', s1)
return s1从图上看,大阪竟然和东京很接近,我去查了格式化之后的文本,东京出现2637次,大阪出现1443次,还是差了很多的;基本信息中也分析了,东京占比非常大;
其他地名出现的次数,也大体统计了一下,神奈川是653次,名古屋是621次,千叶是554次,福冈是546次,横滨是537次,琦玉是428次,京都是357次,爱知县是348次;
词云中有一个“首都圈”,指的是东京都以及周围的县,这里只包括了三个:埼玉县、千叶县、神奈川县;
4、休假情况词云

完全周休2日:指周六日休息;
年末年始:新年假期;
年间休日120日以上:国内法定节日+周末,也差不多120天
感觉这些都没啥说的,正常就应该是这样;
5、福利词云

社会保险完备:出现频率非常高,到原始文本中去搜,出现了1797次,基本每条信息中都有出现;
財形貯蓄:大体搜了一下,主要有两方面,一个是住房储蓄,一个是养老金储蓄,住房储蓄和国内公积金差不多
上边这两个也没啥特别,都算是正常福利;
資格取得支援、資格支援:如果考取资格证或持有资格证,也会有补贴;
服装自由:印象中日本上班族都是西装,服装自由想不出来是什么情景;
研修:各种培训;
还有试用期,大部分3个月,还有6个月的情况;
6、收入
收入再用词云分析就不行了,生成的图片都是一堆数字;
单纯的工资范围也基本没有分析的意义,需要从收入-年龄、收入-工作年限 两个维度分析才能得到一些东西;
采集到的数据里,年收大都给出了例子,这一点日本的招聘网站做的比较好,,比如下面这个:
年収850万円/35歳経験15年/月給51万円+賞与
年収640万円/31歳経験10年/月給36万円+賞与
年収475万円/27歳経験7年/月給32万円+賞与
这是比较理想的情况,能采集到年收入、年龄和工作年限这三个数据,可以得到两个维度的数据;
有的招聘信息只有年收-年龄或者年收-工作年限,这种情况就只采集一个维度;
还有的招聘信息只有年收和进入公司xx年,这种就不考虑了,进入公司xx年只能表示工作年限至少xx年;
还有一种,招聘信息中只给出了月工资,这种也先不考虑,查了下,只有8条数据;
下面最终生成的 年收-年龄 和 年收-工作年限 散点图:
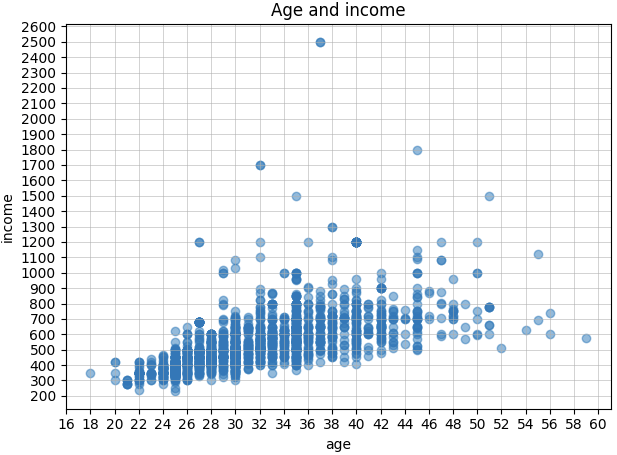
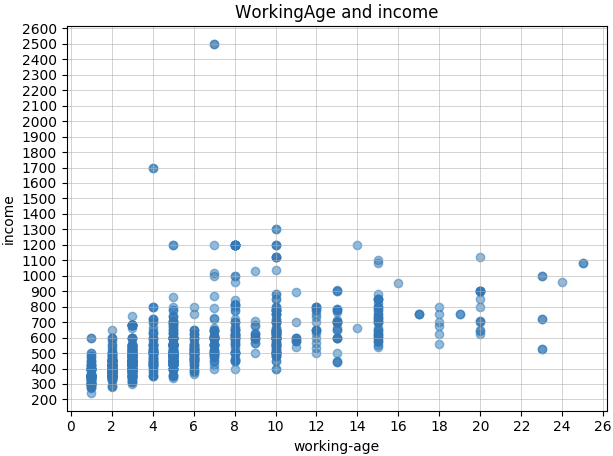
首先看到图表上部一个突兀的点,年收2500万(人民币158万左右)?而且年龄和工作年限都比较靠前,是数据有误吗?从日志中找到id,到库中查到了对应的记录,然后到原网页上确认了一下,数据没有问题,招聘信息中的年收示例是这样的:
初年度年収
500万円~3000万円
モデル年収例 // 年收示例
年収1200万円 / 27歳 マネージャー職 経験5年 // manager
年収1700万円 / 32歳 シニアマネージャー職 経験4年 // Senior manager
年収2500万円 / 37歳 パートナー職 経験7年 // partner
这家公司名称是“株式会社ベイカレント・コンサルティング”,感兴趣的可以去 tenshoku 上搜一下,我现在搜到的是,这家公司发布了4则招聘信息,有技术岗,但年收示例都是上边那个,初年度年收都是500万起;这家公司主要是做经营、咨询(给其他公司制定战略)、外包啥的,技术还用到了AI 和 VR;
接下来继续分析收入数据,从上面两个图中,可以看到:
1、年收入随着年龄、工作年限的增大也有所增长,但感觉涨幅不大(也有可能是2500那个点拉大了图片高度,让下面的数据看起来有些紧凑,斜率要小一些);
2、年收大部分在200-1000万之间,大于1000万的还是比较少;代码中计算了百分比,年龄和工作年限分别为 1.787% 和 3.071%;可以说是行业顶尖人才才能达到的水平了;
3、个人感觉总体年收偏低,比如29岁的年收,中间点大约在500万左右,折合人民币月收2.65万,应该和国内持平或者比国内高一点点吧(对比的数据仅仅来自自己和朋友的工资水平),但考虑到日本消费水平高一些,相比之下显得收入是低那么一点点了,不过实际收入也得看个人能力和公司发展情况了;
4、还一个比较在意的是800万年收的线,不考虑特殊情况,按照总体趋势来看,达到800万年收,最低条件是 32岁工作年限5年,而且必须要处于这些条件的顶端部分,中间点达到800万的情况是没有的… 我在代码中计算了年收大于800万的百分比,年龄维度和工作年限维度下,结果分别为 5.314% 和 6.323%,还是比较低的,我估计短期内是达不到了;
高度专门职申请条件 一文中提到,“家庭年收入大于800万,且有低于7岁的孩子,可以带一方的父母”,如果我老婆也能有正式工作,家庭年收800万估计还是可以的,只算我自己的年收,短期内不太可能;
附上日元人民币兑换表,单位是万,结果保留两位小数(按写文章时的汇率:1日元=0.0635人民币)
| 日元年收入 | 人民币年收入 | 人民币月收入 |
| 400 | 25.39 | 2.12 |
| 500 | 31.74 | 2.65 |
| 600 | 38.09 | 3.17 |
| 700 | 44.44 | 3.70 |
| 800 | 50.79 | 4.23 |
| 900 | 57.13 | 4.76 |
| 1000 | 63.48 | 5.29 |
其他分析
未完待续,还在考虑接下来要怎么分析;
在画上面收入散点图的时候,发现画出一个好的图表还是有点儿难度的,所以接下来要去学习 matplotlib 画图,能够让数据更好地通过图表表现出来,最近应该不会更新这篇文章了;